New AMD EPYC 4005 and Ryzen Pro 9000: Hardware Digest for September
September was a packed month for the hardware industry. Market leaders unveiled new processors and GPUs, while innovative startups launched their own accelerators. In this hardware digest, we’ll explore the key releases from September, dive into new solutions from emerging vendors, and share our insights on the latest trends in AI hardware.

Server Platforms
MSI Servers with NVIDIA RTX Pro 6000 Blackwell Edition GPUs

MSI has unveiled two new servers based on the NVIDIA MGX modular architecture: the 4U CG480-S5063 and the 2U CG290-S3063. Both are designed for AI workloads and feature NVIDIA RTX Pro 6000 Blackwell Server Edition accelerators with 96 GB of memory.
Features of the CG480-S5063 (4U)
- Dual Intel Xeon 6500P / 6700P / 6700E series processors (up to 350W TDP).
- Up to 32 DDR5 slots (RDIMM / MRDIMM) per CPU.
- Up to 20 front-facing E1.S NVMe bays (PCIe 5.0 x4).
- Two internal M.2 slots (2280 / 22110) via PCIe 5.0 x2.
- Expansion options include eight double-width PCIe 5.0 x16 slots, supporting up to eight accelerators.
- Air cooling with hot-swappable fans.
- Four 3200W power supply units (80 PLUS Titanium certified).
The 2U CG290-S3063 model features a single Intel processor, half the memory slots, and support for up to four GPUs. Both systems are designed to offer an excellent price-to-performance ratio by balancing total VRAM with overall cost.
With their rich I/O, NVMe storage, and modern memory, these servers are well-suited for both AI training and inference. They align with the current trend of integrating powerful accelerators into modular, high-density server platforms.
Giga Computing's AMD & Intel Blade Servers

Gigabyte's Giga Computing division has announced the B343 series of blade servers, targeting enterprise, cloud, and edge workloads. Available in two 3U versions—the AMD-based B343-C40 and the Intel-based B343-X40—each chassis houses ten nodes with flexible memory and networking configurations.
- Form Factor: 3U chassis with ten air-cooled nodes.
- Node Design: Each node is a self-contained server with its own CPU, memory, I/O, and network interfaces.
- Power: Four 2000W or two 3200W PSUs (80 PLUS Titanium).
The B343-C40 supports AMD EPYC Embedded 4005 (Grado) or Ryzen 9000 series processors, while the B343-X40 is designed for Intel Xeon 6300/E-2400 CPUs.
Each node features up to four DDR5 ECC slots, one M.2 2280/22110 slot (PCIe 3.0 x1), two SFF NVMe/SATA slots, one FHHL expansion slot (PCIe 5.0 x16), and three OCP NIC 3.0 slots (PCIe 4.0 x4). Various network port configurations are supported, with a maximum of two 25 GbE ports.
Packing ten servers into a 3U chassis delivers high density for cloud, edge, and scalable deployments. The choice between AMD and Intel provides the flexibility to optimize for specific workloads and ecosystems.
Processors
AMD EPYC Embedded 4005 for the Edge

AMD has introduced the EPYC Embedded 4005 processors for industrial and edge systems like factory servers and next-generation firewalls. These new CPUs extend the EPYC 4005 Grado lineup and are based on the Ryzen 9000 architecture.
Key Features
- Zen 5 architecture, 4nm process technology, and chiplet design.
- Compatibility with the AM5 socket.
- Support for DDR5-5600 ECC, 28 PCIe 5.0 lanes, and AVX-512 instructions.
- Up to 128 MB of L3 cache in the top model with 3D V-Cache.
- Integrated AMD Infinity Guard security features.
- Flexible TDP ranging from 65W to 170W.
- A 7-year supply cycle, crucial for industrial solutions.
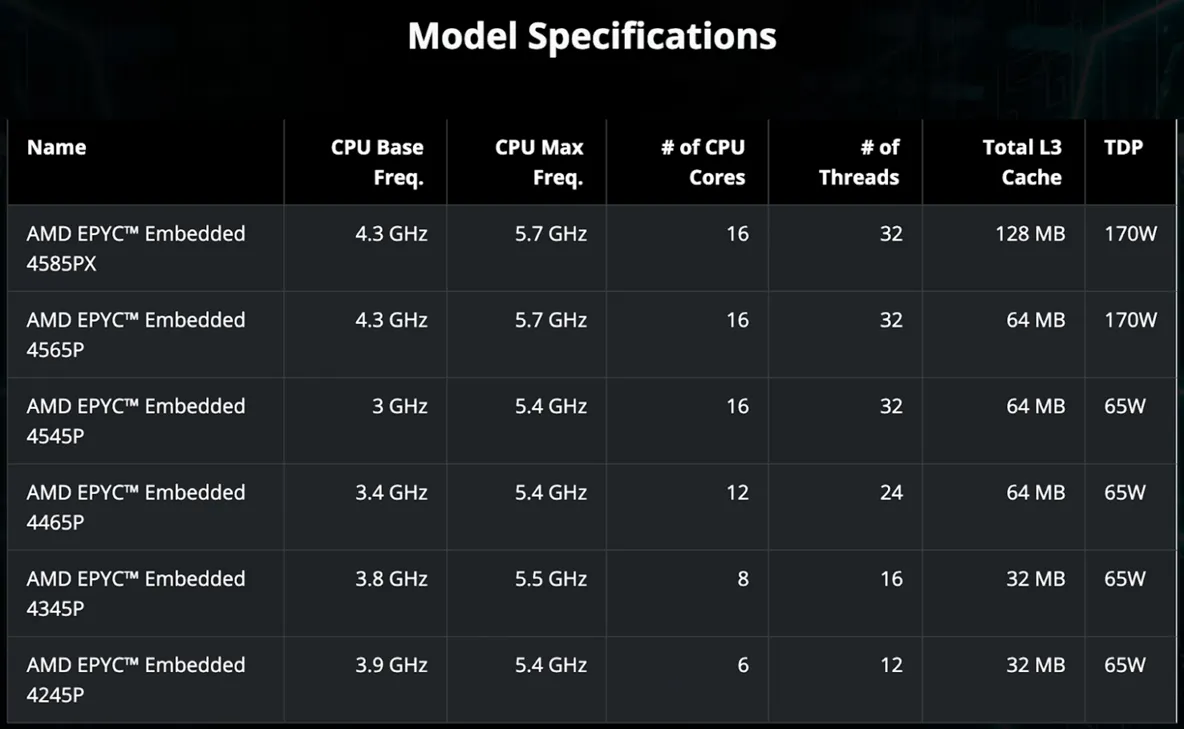
The AMD EPYC Embedded 4005 family brings server-grade features like AVX-512, PCIe 5.0, and DDR5 ECC to a form factor suitable for edge, embedded, and NGFW applications. Its flexible TDP and long-term support make it a viable solution for system integrators and edge infrastructure operators.
AMD Ryzen Pro 9000 for Workstations

AMD has quietly updated its business processor lineup by adding the Ryzen Pro 9000 series, based on the Zen 5 architecture. These are professional versions of the consumer Ryzen 9000 CPUs, enhanced with security and enterprise management features for workstations and business PCs.
Key Features
- Based on the Zen 5 architecture.
- Utilizes the AM5 socket.
- Maintains a 65W TDP across all models.
- Includes AMD PRO technologies for enhanced security, memory protection (Memory Guard), and manageability.

This "soft launch" is likely aimed at OEM partners. The Ryzen Pro 9000 series offers an important upgrade for the workstation and corporate PC market, delivering the higher IPC and clock speeds of Zen 5 with a strong focus on security and manageability, all without increasing TDP.
GPUs and Accelerators
Innosilicon Fenghua 3: China's First Full-Featured RISC-V GPU

Innosilicon has unveiled Fenghua 3, China's first full-featured, domestically designed GPU based on the open RISC-V architecture and compatible with CUDA. The new accelerator targets AI computing, model inference, scientific visualization, and cloud gaming.
Key Features
- Up to 112 GB of HBM memory, a record for a Chinese GPU.
- Based on the OpenCore RISC-V Nanhu V3 architecture, moving away from the PowerVR used in previous models.
- Supports DirectX 12, Vulkan 1.2, OpenGL 4.6, and hardware ray tracing.
- A single accelerator can handle models up to 72 billion parameters, while an eight-GPU cluster can run models like DeepSeek 671B.
- Claimed compatibility with CUDA, simplifying the adaptation of existing AI frameworks.
Fenghua 3 is also the first Chinese graphics card to support the YUV444 format for maximum color accuracy, a significant advantage for video editing and CAD. Furthermore, it's the world's first GPU with hardware support for DICOM, allowing for the correct display of X-rays, MRIs, and CT scans on standard monitors.
The release of Fenghua 3 marks a strategic shift for China, moving from reliance on licensed GPU technology to fully proprietary architectures. Its use of RISC-V and claimed CUDA compatibility represent a major step toward a self-sufficient graphics ecosystem.
Metis M.2 Max: An Accelerator for AI Inference

Dutch startup Axelera AI has announced Metis M.2 Max, an enhanced version of its Metis M.2 module designed for AI inference on edge devices. The company claims it boosts performance for LLM and VLM tasks through increased memory bandwidth, improved cooling, and enhanced security.
Key Features
- Form Factor: M.2 2280 (M-Key) with a PCIe 3.0 x4 interface.
- Architecture: Based on the Metis AIPU with four RISC-V cores.
- Memory: Up to 16 GB with double the bandwidth of the original Metis M.2.
- Security: Integrated Root of Trust, secure boot, and protection against unauthorized software.
- Power Consumption: Averages 6.5W.
The device reportedly delivers a 33% performance increase in convolutional neural networks (CNNs) and doubles the token generation speed for LLM and VLM models. It's compatible with the Voyager SDK, which simplifies model optimization and application integration.
The Metis M.2 Max maintains a compact and energy-efficient profile while offering significant improvements in memory bandwidth and security. It is particularly compelling for systems that require a balance of performance, size, and resilience in demanding operating conditions.
NVIDIA Blackwell Ultra: Key Details and Advantages

NVIDIA has revealed architectural details of Blackwell Ultra, an evolution of its Blackwell accelerator. The update includes a higher transistor count, a more powerful tensor core engine, and expanded memory, targeting AI inference, reasoning models, and high-density data center scaling.
Architecture and Specifications
- Dual-Die Design: Blackwell Ultra maintains a dual-die configuration connected by an NV-HBI interface with up to 10 TB/s of bandwidth.
- Transistor Count: A total of 208 billion transistors.
- Tensor Cores: The architecture includes 160 Streaming Multiprocessors (SMs) and approximately 640 fifth-generation Tensor Cores optimized for low-precision formats (NVFP4, FP8).
- New FP Format: NVFP4 is a new 4-bit floating-point format that NVIDIA claims offers accuracy close to FP8 while using up to 3.5 times less memory than FP16.
Compared to the original Blackwell, NVFP4 performance has increased from 10 to 15 PFLOPS. For attention layers, the throughput of special function units (SFUs) has been doubled, accelerating computations on long contexts and reducing time-to-first-token.
Memory Subsystem and Interconnect
- Memory: 288 GB of HBM3e with an 8192-bit bus, providing 8 TB/s of bandwidth.
- NVLink 5: Enables the connection of up to 576 GPUs into a single compute fabric.
- Host Interface: PCIe 6.0 x16.
- Networking: Integrates ConnectX-8 SuperNIC and Quantum-X800 InfiniBand / Spectrum-X Ethernet, with up to 800 Gb/s per GPU.
Blackwell Ultra's architectural changes signal a clear shift toward inference and reasoning tasks. The increased memory allows large models to reside entirely on the GPU, reducing latency. This positions the new accelerator as the foundation for modular and scalable AI factories.
D-Matrix JetStream Card for Distributed Inference

Startup d-Matrix has introduced JetStream, a specialized I/O card designed to distribute AI inference workloads across servers. It works with the company's Corsair accelerators to reduce latency without requiring changes to existing network infrastructure.
Key Features
- Form Factor: PCIe 5.0 x16 expansion card.
- Networking: Two 200 GbE ports or one 400 GbE port with standard Ethernet (QSFP-DD).
- Power Consumption: Approximately 150W, cooled by a heatsink and heat pipes.
A single JetStream card serves up to four Corsair accelerators. The card eliminates the I/O bottleneck when scaling inference workloads, especially when a model is distributed across multiple servers, achieving a claimed network latency of just 2 μs. The company asserts that their solution is up to 10 times faster and three times more power-efficient than GPU-based alternatives for models over 100 billion parameters. Samples are available now, with mass production planned for the end of the year.
Memory
SK hynix Finalizes HBM4 Development

SK hynix has announced the completion of its HBM4 memory development. The company has already sent 12-layer samples to clients and is preparing for mass production in the second half of 2025. HBM4 is set to become a key component in future AI accelerators like NVIDIA's Rubin, offering double the bandwidth and significantly improved power efficiency over HBM3/3E.
Key Features
- 2048-bit Interface: Doubles the width compared to HBM3/E, a first since 2015.
- Data Transfer Rate: Over 10 Gbps per pin, 25% higher than the official JEDEC standard for HBM3E.
- Bandwidth: Twice that of HBM3E.
- Power Efficiency: Improved by 40%.
- AI Performance: Expected to boost AI accelerator performance by up to 69% by eliminating memory bottlenecks.
The memory is manufactured using a fifth-generation 10nm-class (1β nm) process and an innovative Advanced MR-MUF (Molded Underfill) assembly technique, which ensures mechanical stability and better heat dissipation. This new memory will be used in upcoming products from NVIDIA, AMD, Broadcom, and other AI industry leaders.
Storage
Solidigm D7-PS1010: A Liquid-Cooled E1.S SSD

Solidigm (an SK hynix brand) has introduced one of the world's first liquid-cooled enterprise SSDs, the D7-PS1010 E1.S. It is designed for high-density servers that lack traditional air cooling. The key feature is a cold plate that contacts both sides of the hot-swappable drive.
Key Features
- Form Factor: E1.S with 9.5mm and 15mm thickness options.
- Technology: Based on 176-layer 3D TLC NAND and a PCIe 5.0 x4 (NVMe) interface.
- Capacities: Available in 3.84 TB and 7.68 TB for the liquid-cooled version.
- Speeds: Sequential read speeds up to 14,500 MB/s and write speeds up to 10,500 MB/s.
Solidigm is working with server manufacturers to integrate this solution into AI infrastructures, including systems based on the NVIDIA HGX B300. Unlike traditional liquid cooling systems that cool only one side of an SSD, this new design cools both sides, improving thermal balance and reducing the risk of throttling. By eliminating the need for dedicated drive fans, it enables even denser server configurations and could accelerate the transition of data centers to fully liquid-cooled environments.
Do you think data centers will eventually transition to fully liquid cooling? And is it necessary? Stay tuned for more hardware news.