Apache Cloudberry History, Architecture, and Functions
The Origins of Apache Cloudberry
Apache Cloudberry is an open-source, massively parallel processing (MPP) DBMS created by the original developers of Greenplum. The core idea was to retain Greenplum's robust distributed platform while upgrading its underlying engine to a modern PostgreSQL core, making it a powerful solution for analytical workloads.
The Greenplum Legacy and Cloudberry's Rise
Cloudberry was initiated by its developers in June 2022 and transitioned to an open-source model in 2024. Shortly after, the original Greenplum project on GitHub was archived and became closed-source. The new project quickly gained traction, joining the Apache Incubator in late 2024 and amassing over 1,000 stars on GitHub.
The fork was necessary due to several challenges facing the Greenplum project:
- Stagnant Development: Greenplum's development pace had slowed, falling behind modern performance requirements and lacking crucial features for cloud environments and data lakes.
- Single-Vendor Control: The project was always controlled by a single company, with no open governance model for community participation in decision-making.
- Ecosystem Instability: Frequent changes in ownership created uncertainty among partners and the open-source community.
Cloudberry Architecture
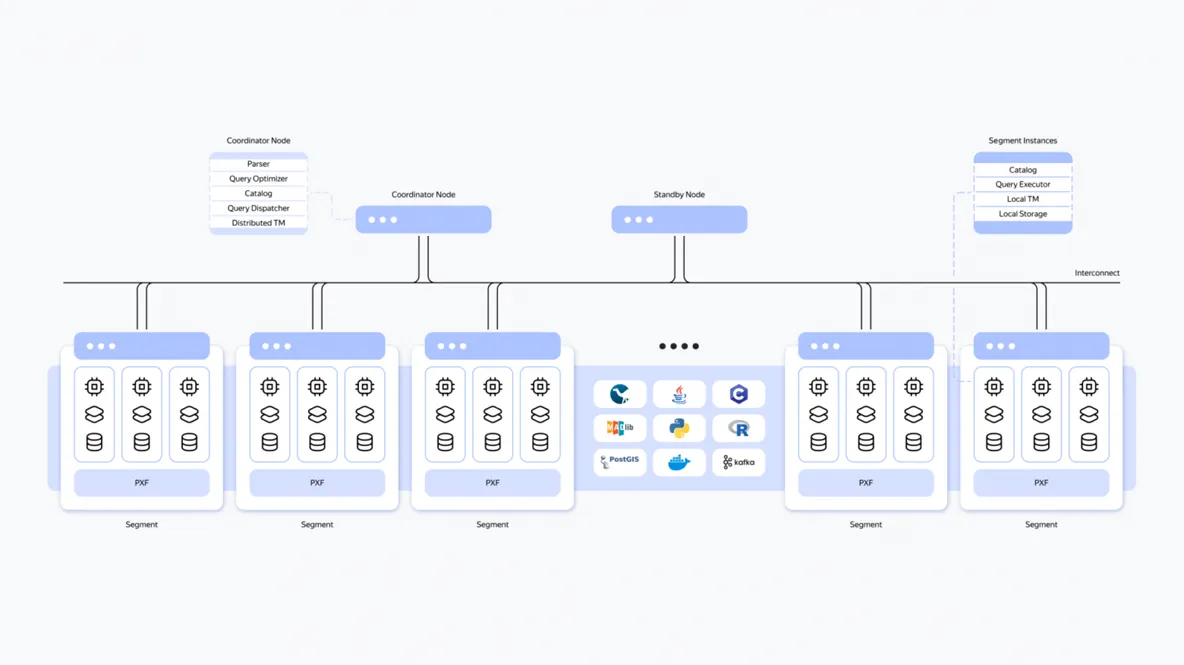
Upgraded Core Engine and Platform Features
By upgrading to the PostgreSQL 14 core, Cloudberry inherits a wealth of modern data types and features:
- Modern data types including Multi-range, JSON, JSONB, and XML.
- UPSERT functionality via
INSERT ... ON CONFLICT. - Hash Partitioned Tables.
- Concurrent re-indexing with
REINDEX CONCURRENTLY. - Incremental sorting to boost performance on pre-sorted data.
- Abbreviated keys for faster sorting.
- Strong password authentication using SCRAM-SHA-256.
- Advanced system views like
pg_stat_*. - Bloom filters for BRIN indexes.
Vectorized Query Execution Engine
Cloudberry includes a high-performance vectorized query engine, enabled by default (vector.enable_vectorization). It processes data in batches, supporting a wide range of data types and vectorized operators like Scan, Agg, Hash Join, and Sort.
Instead of simply adopting PostgreSQL's execution model, Cloudberry implements its own highly efficient algorithms for operations like Hash Join and aggregation.
- Thread-Based Parallelism: Utilizes threads instead of processes for faster execution.
- Improved CPU Utilization: The vectorized engine makes better use of modern CPU capabilities.
- Advanced Hardware Optimization: The new PAX columnar storage format unlocks optimizations like SIMD.
- Superior Compression: Columnar storage allows for higher compression ratios compared to traditional algorithms like zstd.
Multi-Cluster Queries
Using Foreign Data Wrappers (FDW), Cloudberry can execute queries across multiple clusters. Unlike postgres_fdw, the query dispatcher node doesn't become a bottleneck:
- Distributed Joins: The
gp_foreign_serverhint allows the optimizer to perform join operations on the local cluster. - Pushdown Optimization: The optimizer pushes Join and Aggregation operators to the target Cloudberry cluster, minimizing intermediate data transfer.
Aggregation Pushdown
A crucial optimization for OLAP workloads, Aggregation Pushdown expands the optimizer's search space. It rewrites the query to perform aggregation before a join, drastically reducing the amount of data that needs to be joined and improving execution time. The optimizer uses cost-based analysis to determine whether to apply this rewrite, always selecting the most efficient plan.
Parallel Execution
Cloudberry leverages the parallel execution feature from PostgreSQL, allowing a single query to use multiple CPU cores. This improves performance and can reduce the number of required instances. The query planner automatically determines the number of parallel workers based on the data volume. Supported operations include:
- Sequential Scan
- Index Scan & Index-Only Scan
- Bitmap Heap Scan
- Hash Join, Nested Loop Join, and Merge Join
Incremental Materialized Views and Query Rewriting
- Incremental Updates: The system efficiently captures new and modified data rows using triggers, simplifying the view refresh operation.
- Synchronous or Asynchronous Rewrites: Query rewriting can be configured to happen either synchronously or asynchronously.
- Semantic Consistency: Different rewrite rules are applied for various query operators (Filter, Join, Agg) to ensure consistency.
- Cost-Based Optimization: The optimizer can replace a sub-tree in a query plan with one that uses the materialized view, choosing the path with the lowest estimated cost.
- Delta-Aware Rewriting: For asynchronously updated views, the rewrite process intelligently accounts for incremental data changes.
PAX: A Hybrid Columnar Storage Format
A key innovation is PAX (Partition Attributes Across), a block-based storage format designed for the vectorization engine. It overcomes the limitations of Greenplum's Append-Optimized Column-Oriented (AOCO) storage, which creates a separate file for each column and leads to excessive, costly file open/close operations for tables with many columns.
With PAX, tables are divided into row groups, and within each group, data is stored by column. This enables efficient column projection pushdown—if a query only needs one column, only the data for that column is read. Filters can also be used to skip entire blocks of irrelevant data.
- Pushdown filtering and column projection
- Batched I/O for contiguous columns
- Full support for all fixed and variable-length data types
- Advanced data compression and encoding
- Block skipping for faster scans
- Native support for vectorized execution
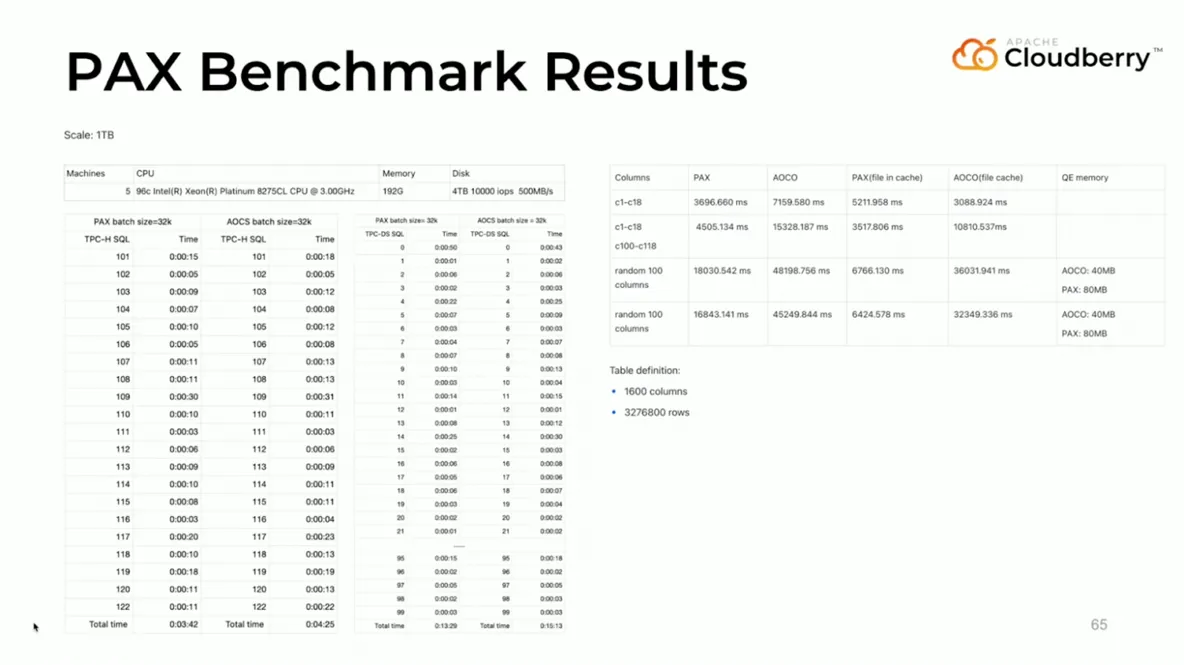
PAX Performance: Benchmark tests show that PAX delivers a significant performance boost. In a test on a table with 1,600 columns, PAX clearly outperformed the traditional AOCO storage format.
Cloudberry provides a multi-layered approach to data security, with robust features for authentication, authorization, and data protection.
Level 1: Unified Authentication
- Support for various ciphertext, encryption, and hashing algorithms (MD5, SHA-256).
- Kerberos authentication.
- Password complexity and account security policies (e.g., lockouts after failed attempts).
- Integration with external authentication systems like LDAP.
Level 2: Granular Authorization
- Role-based access control with different permission levels.
- Fine-grained privilege management (SELECT, UPDATE, etc.) for objects like schemas, tables, and views.
- Row-Level Security (RLS) policies.
Level 3: Data Protection and Encryption
For data-at-rest security, Cloudberry includes the pgcrypto component and supports Transparent Data Encryption (TDE) with AES and SM4 algorithms. Dynamic data masking is also available to protect sensitive information in development and testing environments, offering built-in algorithms like Random, Flaking, and SHA.
Cloudberry can manage unstructured data using a straightforward, catalog-based process:
- A user uploads unstructured data files.
- Cloudberry creates an index and a catalog entry to generate metadata for the files.
- The database moves the data file into a tablespace (local or cloud-based).
- Users can query file metadata (e.g., path, size, modification date) using simple SQL.
- This metadata can then be used in other queries or applications to process the data.
Feature Summary
Performance Features
- REINDEX CONCURRENTLY
- Aggregation Pushdown
- Incremental sorting
- Query Pipelining
- BRIN indexes (multi-minmax, Bloom)
- Parallel query execution
- Runtime filters for joins
Security Features
- Transparent Data Encryption (TDE)
- Trusted Extensions
- SCRAM-SHA-256 Authentication
- Row-Level Security (RLS) policies
General Enhancements
- EXPLAIN (ANALYZE) support
- HASH partitioned tables
- Recursive CTEs (SEARCH and CYCLE)
- Backup integrity verification (pg_verifybackup)
- Coordinator auto-failover
- Kubernetes deployment support