PostgreSQL 18 Released! Let's review it

PostgreSQL 18 has beed released, and it's not just a minor update, but a real breakthrough for developers and database administrators. We'll look at the key new features — asynchronous I/O for faster reading, support for UUID version 7 with improved sorting, skip scans in B-tree indexes, virtual computed columns, and even OAUTH 2.0 for authentication. All this makes Postgres even faster, more flexible, and more modern.
Asynchronous Input/Output (I/O)
Postgres 18 adds support for asynchronous I/O. This means faster read operations in many use cases. It is also part of a larger performance improvement program planned for future versions of Postgres, including potential support for multithreading.
What is Asynchronous I/O?
When data is not present in the shared memory buffers, Postgres reads it from the disk, which requires an I/O operation. With synchronous I/O, each individual disk read operation is blocking—the backend process responsible for executing the query has to wait for the I/O result. In high-load databases with high activity, this can and does become a bottleneck.
Postgres 18 introduces asynchronous I/O, allowing workers to use idle time more efficiently and increase overall system throughput through batch processing of reads. In current versions, Postgres largely relies on the operating system's discretion for I/O management—for example, read-ahead for sequential scans or using posix_fadvise in Linux for operations like Bitmap Index Scans.
Moving this logic into the DBMS itself using asynchronous I/O will allow for greater predictability and better performance with batch processing at the database level. A new system view - pg_aios
Write operations will remain synchronous — this is necessary to comply with ACID principles!
By default, Postgres will have the io_method = worker
UUID Version 7
UUIDs are randomly generated strings that are globally unique and often used as primary keys. UUIDs
The new UUID v7 standard appeared in mid-2024 as a result of a series of standard updates. Previously, Postgres supported UUID v4. However, when working with large tables, v4 had problems with sorting and indexing due to the high randomness of values, which led to index fragmentation and poor data locality.
UUID v7 solves these problems. It remains random, but the first 48 bits (12 characters) represent a timestamp (essentially a unix timestamp),
The remaining bits are random. This improves the locality of data inserted at around the same time and, consequently, reduces some of the load on indexes.
The timestamp is a hexadecimal value (i.e., a number in base-16). For example, a UUID

Here's what the DDL for UUID
CREATE TABLE user_actions (
action_id UUID PRIMARY KEY DEFAULT uuidv7(),
user_id BIGINT NOT NULL,
action_description TEXT,
action_time TIMESTAMPTZ NOT NULL DEFAULT NOW()
);
CREATE INDEX idx_action_id ON user_actions (action_id);B-tree skip scans
Postgres 18 is expected to see a significant performance boost when using some multi-column B-tree indexes.
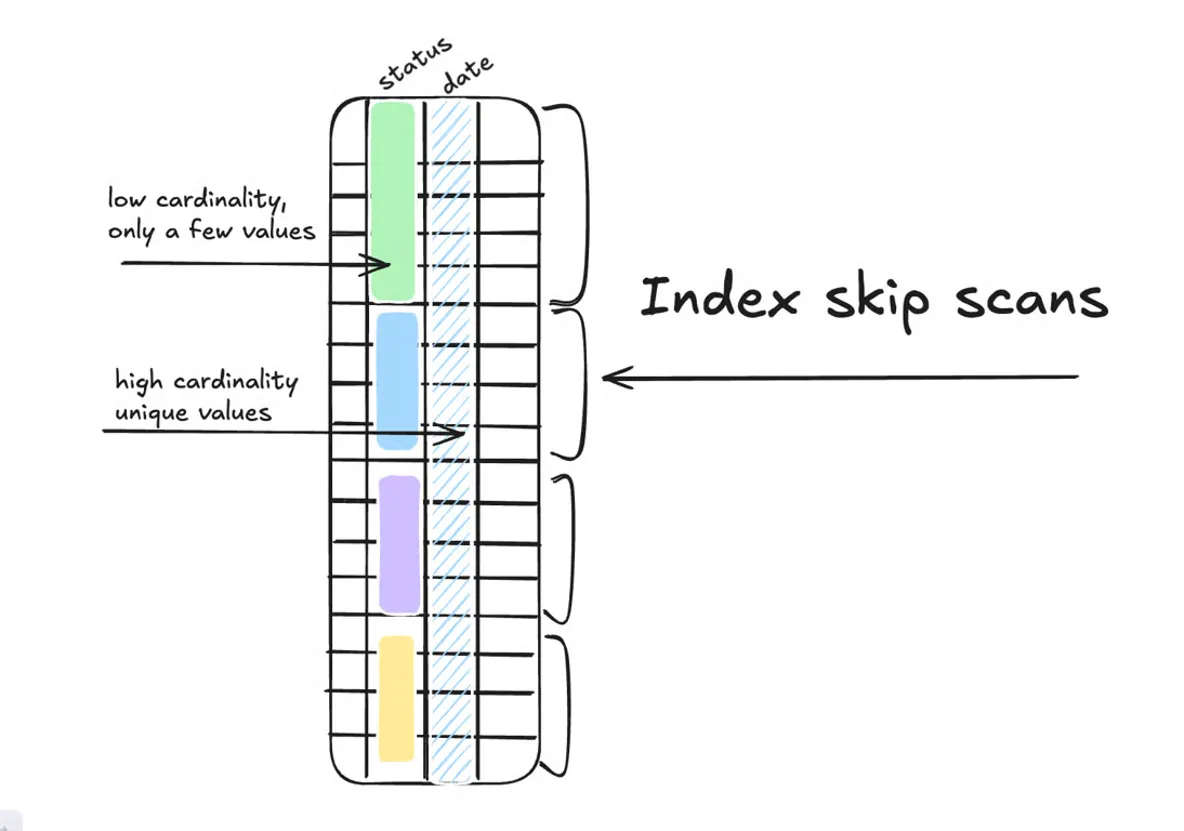
In Postgres, if you have an index on the columns (statusdatestatusdatestatus
In Postgres 17 and earlier, this same index cannot be used for queries that filter only on the date field. In such cases, it was necessary to either create a separate index on date, or the DBMS would perform a sequential scan of the table followed by filtering.
In Postgres 18, it will be possible in many cases to automatically use such a multi-column index even in queries concerning only the date
The optimization works in cases where queries do not use the leading columns in their conditions, and the skipped columns have low cardinality (i.e., a limited number of unique values).
For example, if we have a salesstatusdate
CREATE INDEX idx_status_date
ON sales (status, date);An example query might contain a WHEREstatus
SELECT * FROM sales
WHERE date = '2025-01-01';The query execution plan does not indicate that a skip scan is used, so you will see a regular Index Scan, which shows the index conditions.
QUERY PLAN
-------------------------------------------------------------
Index Only Scan using idx_status_date on sales (cost=0.29..21.54 rows=4 width=8)
Index Cond: (date = '2025-01-01'::date)
(2 rows)Before version 18, a full table scan would have been performed because the leading column of the index is not used in the query. However, with the introduction of skip scans in Postgres 18, the same multi-column index can be used for an index scan.
In Postgres 18, because the status field has low cardinality and contains only a few unique values, a composite index scan can be performed. Please note: this optimization only works for queries using the = operator and does not apply to inequalities or ranges.
All of this happens automatically at the Postgres query planner level—nothing needs to be enabled. The idea is to improve performance in analytical scenarios where filter conditions change frequently and do not always match existing indexes.
The planner will decide for itself whether it is appropriate to use a skip scan, based on table statistics and the number of unique values in the skipped columns.
Virtual Computed Columns
PostgreSQL 18 introduces virtual computed columns. Previously, computed columns were always saved to disk. This meant that their values were calculated during insert or update operations, which added a certain amount of write overhead.
In PostgreSQL 18, virtual computed columns now become the default type for all computed columns. If you define a computed column without explicitly specifying STORED
CREATE TABLE user_profiles (
user_id SERIAL PRIMARY KEY,
settings JSONB,
username VARCHAR(100) GENERATED ALWAYS AS (settings ->> 'username') VIRTUAL
);This is an excellent update for those working with JSON data: queries become simpler, and data changes or normalization can now be performed 'on the fly' when needed.
Please note: virtual computed columns cannot be indexed because they are not stored on disk. To index JSONBSTORED
OAUTH 2.0 Support
Good news for those who use Okta, Keycloak, and other authentication management services: Postgres is now compatible with OAUTH 2.0. Configuration is done in the main authentication configuration file, pg_hba.conf.
The OAUTH system uses special access tokens, where the client application presents a token instead of a password to confirm identity. The token is 'opaque', with its format defined by the authorization server (within the OAuth2 framework). This innovation eliminates the need to store passwords in the database and also allows for the implementation of more robust security measures—such as multi-factor authentication (MFA) and single sign-on (SSO), managed by external identity providers.
The Postgres 18 release also includes many other improvements
Postgres 18 includes an impressive 3,000 commits from over 200 authors. In addition to new features, many internal improvements and optimizations have been made to the system—primarily in the query planner and other key components. Even if you don't plan to use the new optional features, you will still benefit from performance improvements (e.g., through asynchronous I/O), bug fixes, and security updates. Regular updates are a wise strategy.