OpenAI Adds GPT-4.1 to ChatGPT
For paid users.
- The non-reasoning GPT-4.1 is available in the ChatGPT model list for Plus, Pro, and Team subscribers, OpenAI announced on X. Enterprise and Edu users will get access in the coming weeks.
- The GPT-4.1 mini model will replace GPT-4o mini in ChatGPT. It will be available to all users.
- OpenAI introduced GPT-4.1, GPT-4.1 mini, and GPT-4.1 nano in April 2025. According to the company, they surpass GPT-4o and GPT-4o mini and are particularly good at writing code and following instructions. Initially, the models were available via API.
How the GPT-4.1 family models differ
A user asked all models in the lineup to create an HTML file for an animation of several rotating hexagons with balls.
Where to test GPT-4.1 and how much it costs
- In OpenAI's API, GPT-4.1 costs $2 per 1 million input tokens and $8 per 1 million output tokens; GPT-4.1 mini — $0.40 and $1.6 respectively; GPT-4.1 nano — $0.10 and $0.40 respectively.
- The developers of the code editor Cursor AI added the model to their service and opened free access — temporarily. A Cursor AI subscription costs from $20 per month.
- Windsurf also allowed free testing of the model — until April 20, 2025. The minimum subscription cost is $15.
How the price and capabilities of GPT-4.1 and competitors compare
- As independent researchers from Artificial Analysis write, GPT-4.1 is smarter and cheaper than GPT-4o. According to their tests, GPT-4.1 outperformed Llama 4 Maverick, Claude 3.7 Sonnet, and GPT-4o, and also matched the new V3 version from DeepSeek.
- GPT-4.1 mini, according to their data, slightly surpasses GPT-4.1 in programming. GPT-4.1 nano is roughly equivalent to Llama 3.3 70B and Llama 4 Scout.
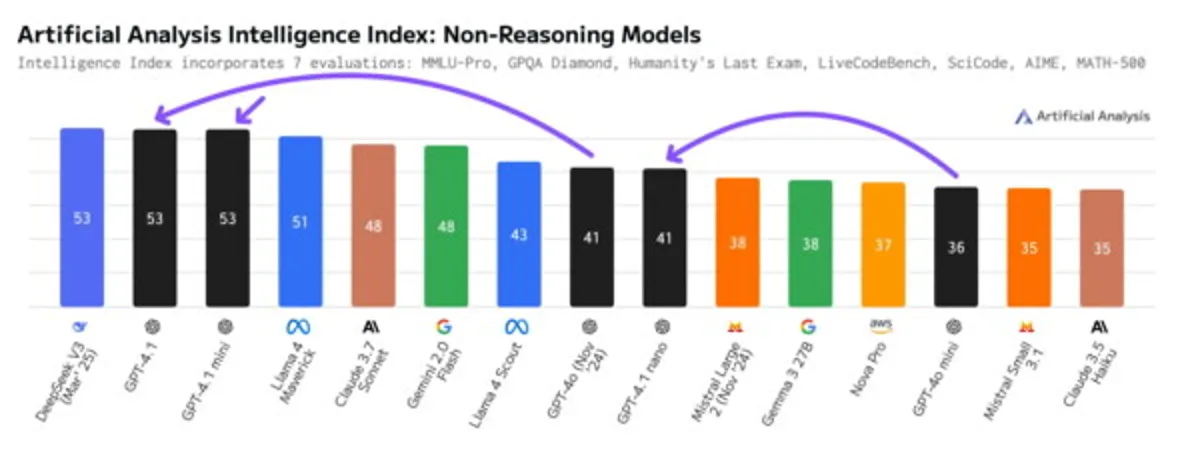
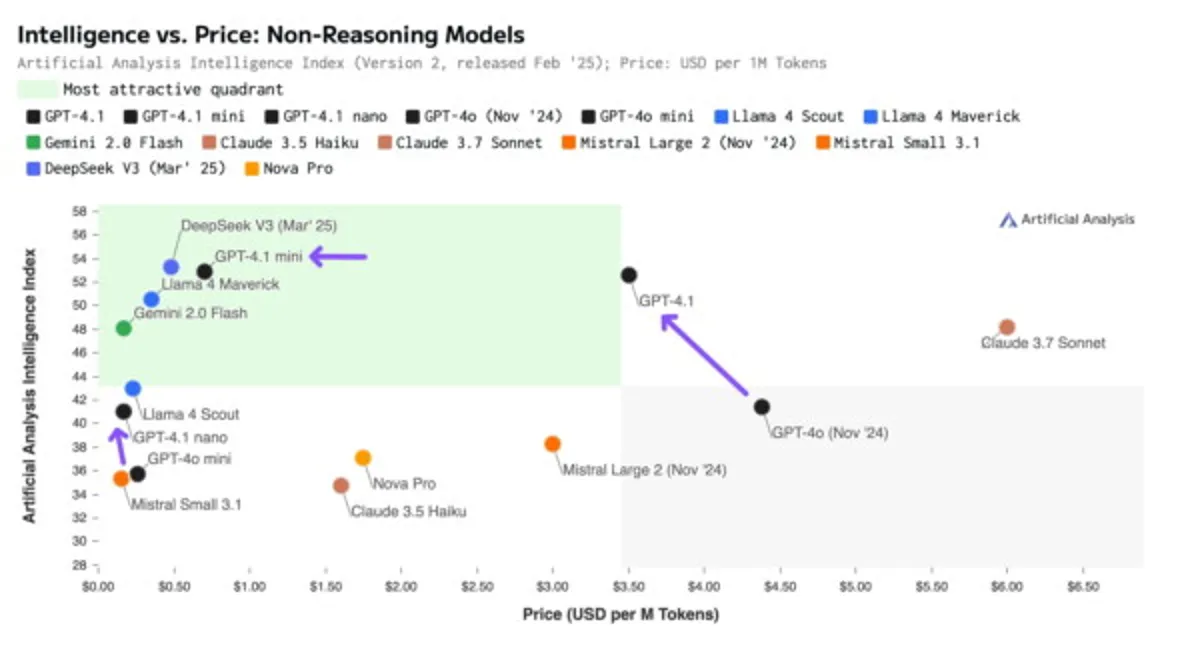
- Artificial Analysis did not test reasoning models. In a general programming test by the code editing platform Aider, among all model types, the new reasoning Gemini 2.5 Pro took first place, while GPT-4.1 was in 13th place, one of the developers noted on X.
- Those who tested the new OpenAI model added in response that they were not surprised by the result: they believe that Gemini 2.5 Pro writes code better — primarily thanks to long chains of reasoning.
What impressions developers are sharing
- One developer tested how the model creates frontend code. Claude 3.7 Sonnet wrote twice as much code but, instead of selecting images, used gray placeholders. The user liked GPT-4.1's result more.
- Another developer asked two models to create a note-taking app. He, on the contrary, rated Claude's result higher, and called GPT-4.1 and other models in the lineup more lazy.
- A developer of educational apps for children noticed that GPT-4.1 reads fewer unnecessary files, makes fewer useless changes, and isn't as verbose.
GPT-4.1 created a "simulator" for learning about physical phenomena in a game format.

Another user tested how models create drawings in SVG format. Prompt: "Create a beautiful SVG with an image of the first three first-generation starter Pokémon in a single HTML file."
- In March 2025, AI enthusiasts developed a humorous creativity test for neural networks, the Minecraft Benchmark. Users choose the best build out of two, without knowing which model made it. Based on these preferences, a model ranking is compiled.
- Currently, the leader is Gemini 2.0 Pro. The developers haven't added GPT-4.1's position yet, but they have already shared the model's first generations.
Glass palaces by GPT-4.1 (right) and Gemini 2.5 Pro Experimental:


Earth "through the eyes" of GPT-4.1 (right) and GPT-4.5:


What to consider in prompts for the new GPT-4.1
- OpenAI adapted GPT-4.1 for creating AI agents and working with long contexts. The developers published instructions for crafting prompts.
- GPT-4.1 can follow instructions more precisely, avoiding the free interpretations that previous models might have allowed, so the main thing is to formulate the request clearly.
- Developers claim that GPT-4.1 can handle even the maximum request length of 1 million tokens. But they advise writing structured instructions—both at the beginning and at the end of a long request.