NVIDIA Introduced a Model That Analyzes Sound, Speech, and Music

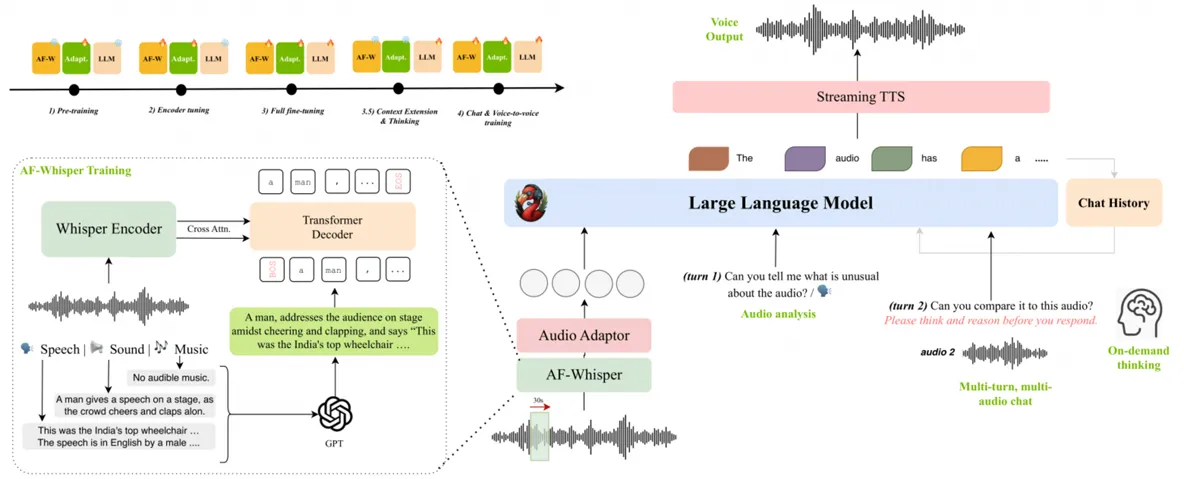
NVIDIA has introduced Audio Flamingo 3, a new multimodal model designed to comprehend and analyze a wide spectrum of audio, including sound, speech, and music. This powerful AI combines a sophisticated tech stack—including an AF Whisper audio encoder and the Qwen 2.5 7B language model—to deliver its impressive capabilities.
Key Capabilities
- Advanced Audio Processing: Processes lengthy audio recordings of up to ten minutes while maintaining context.
- Multi-Turn Conversations: Engages in sophisticated, multi-turn dialogues, moving beyond simple command-and-response interactions.
- Comprehensive Understanding: Accurately recognizes speech, understands context, and analyzes musical fragments and ambient soundscapes.
The Future of Audio Assistants
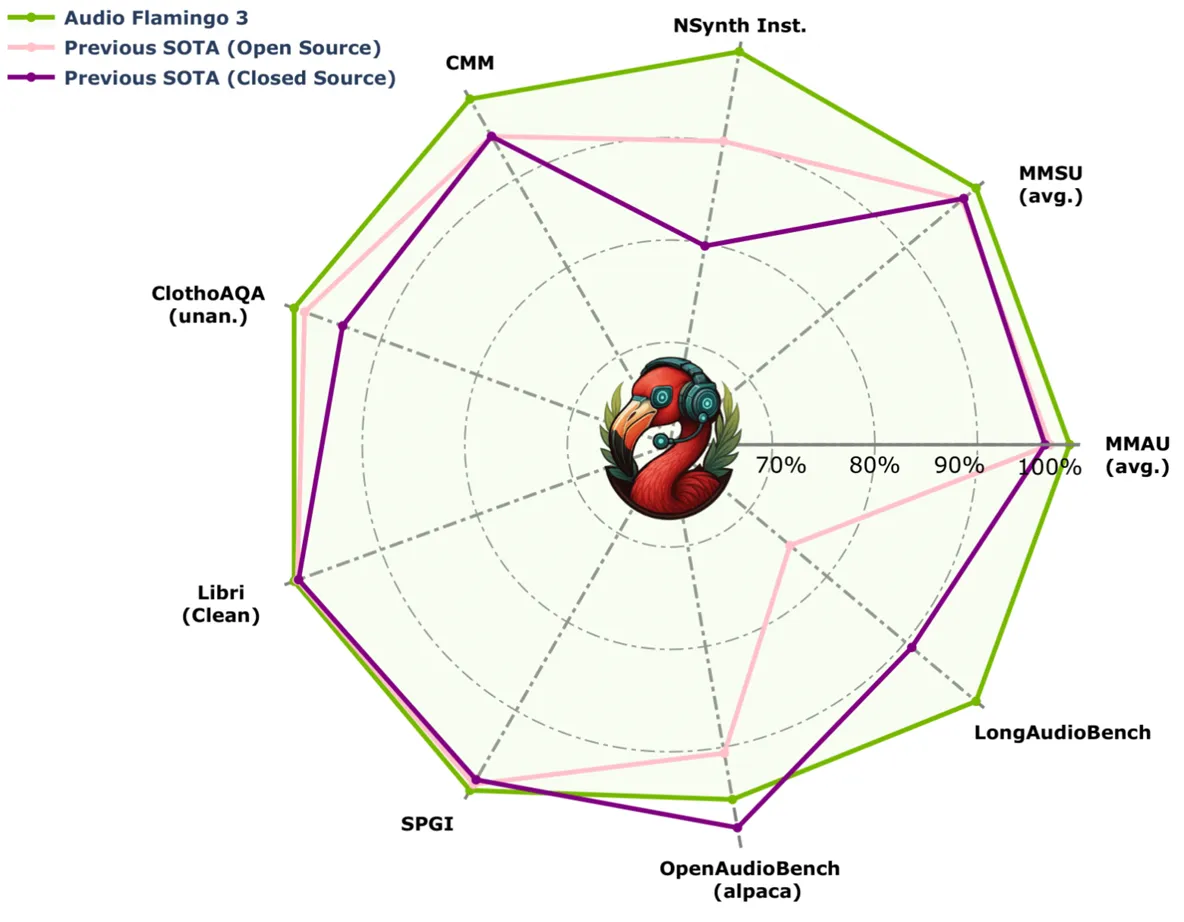
Trained on massive audio datasets, Audio Flamingo 3 already demonstrates outstanding performance in sound comprehension and reasoning tests. This technological leap promises to redefine what's possible for audio-based AI.
This new architecture opens the door to full-fledged audio assistants that can conduct natural conversations and understand human intonation, moving far beyond simple command recognition.
The model is integrated into the NVIDIA ecosystem and is now available for researchers to explore via PyTorch and Hugging Face.