PyTorch Introduced a Framework That Turns Thousands of GPUs Into One Logical Computer
PyTorch is once again advancing AI infrastructure with its latest announcement: Monarch, a revolutionary distributed computing system that lets you control thousands of GPUs from a single Python script.
A New Paradigm for Distributed Computing
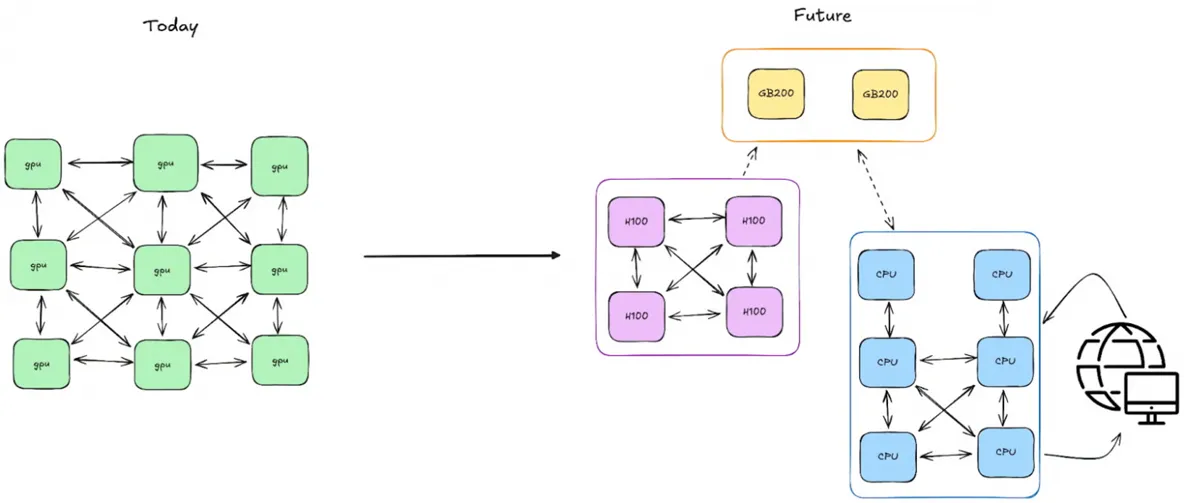
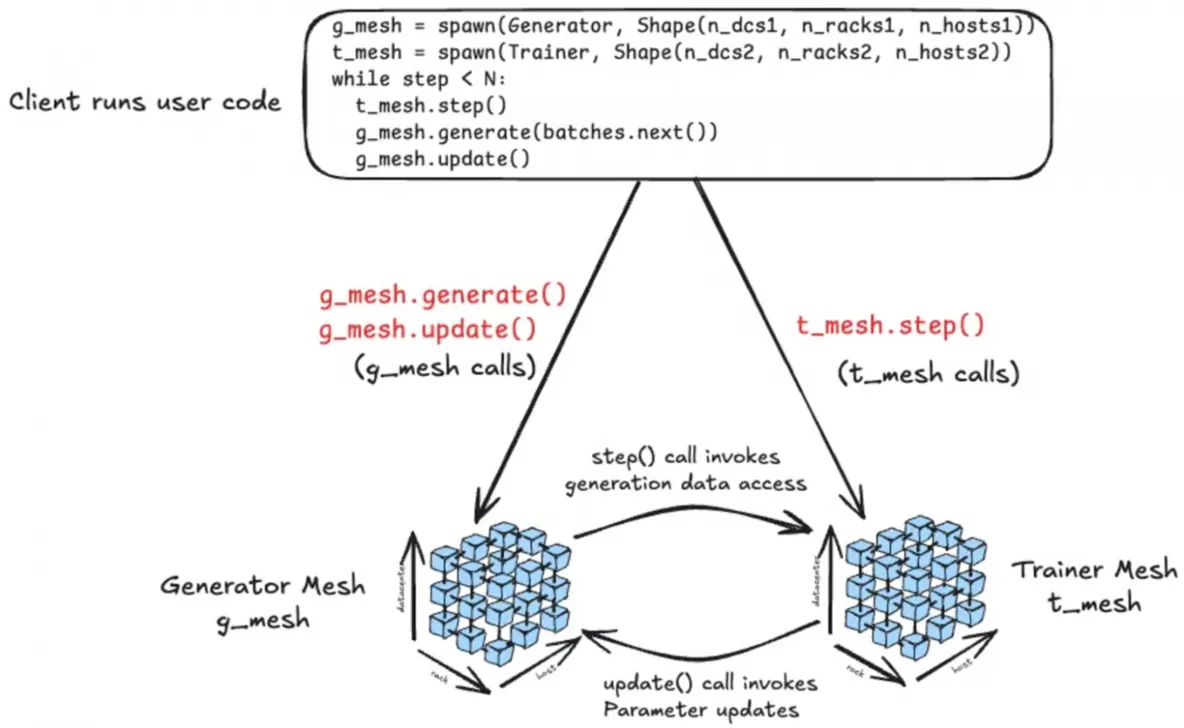
Monarch breaks away from the traditional Single Program, Multiple Data (SPMD) model, where each node runs the same code independently. Instead, you write a single control program, and the framework automatically handles the distribution and synchronization of computations across all nodes.
High-Speed, CPU-Free Communication
At its core, Monarch introduces multi-dimensional computation meshes. These structures enable processes and actors to communicate directly, transferring data from GPU to GPU via RDMA, completely bypassing the CPU. This dramatically cuts overhead and accelerates tasks like reinforcement learning, model fine-tuning, and multi-modal analysis.
Developer-Friendly Features
A major benefit is its seamless integration with the standard Python ecosystem. Developers can use familiar tools like Jupyter Notebooks for real-time, interactive debugging. The system also boasts key enterprise-grade features:
- Dynamic scaling to adjust resources on the fly.
- Built-in fault tolerance for robust operations.
- Simplified and clear error debugging.
The Future of Distributed AI
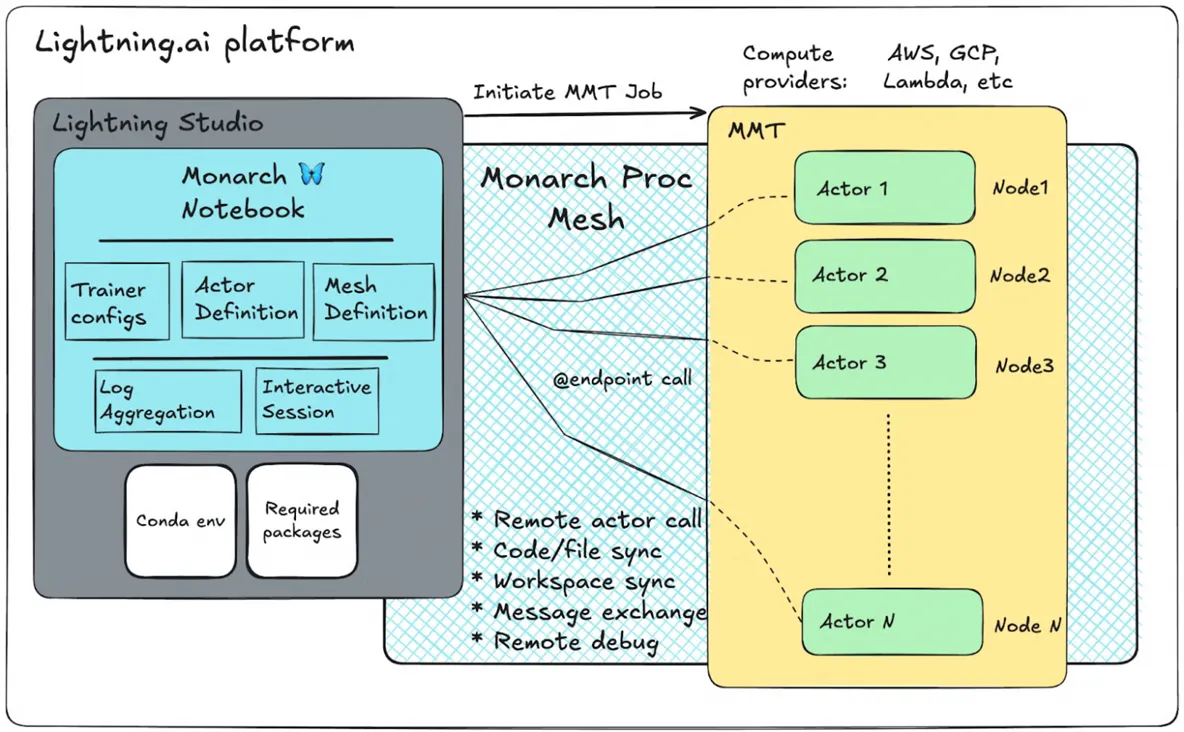
Monarch is already integrated with major platforms like TorchForge, VERL, and Lightning AI, positioning it to become the new standard for distributed machine learning.
In essence, Monarch transforms an entire GPU cluster into a single, unified computational brain, all managed from one interface.