Kimi Introduced a New Model — Kimi-Linear-48B-A3B-Base
The team at Moonshot AI has introduced a major advancement in large model architecture. Their new approach, Kimi Delta Attention (KDA), is a hybrid system that combines Gated DeltaNet and MLA compression. This innovative design enables models to process long contexts with superior reasoning while significantly reducing computational costs.
How It Works: Focusing on Change
The core principle of KDA is efficiency. Instead of recalculating the entire attention mechanism for every new token, it focuses only on the changes. The architecture strategically balances attention with a 3:1 ratio—three parts KDA to one part MLA—ensuring the model maintains the stability and accuracy of larger LLMs but with a fraction of the resource requirements.
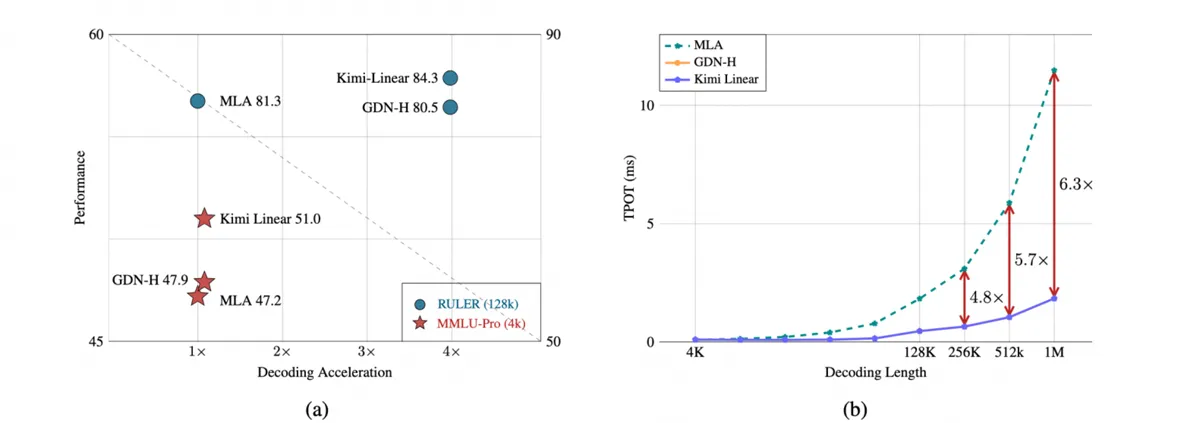
Impressive Performance Gains
The Kimi-Linear-48B model, built on the KDA architecture, delivers remarkable results without compromising on quality:
- Requires up to 75% less memory for its KV cache.
- Achieves a decoding speedup of up to 6.3x on long contexts.
- Outperforms both MLA and GDN-H architectures in complex reasoning and long-chain generation tasks.
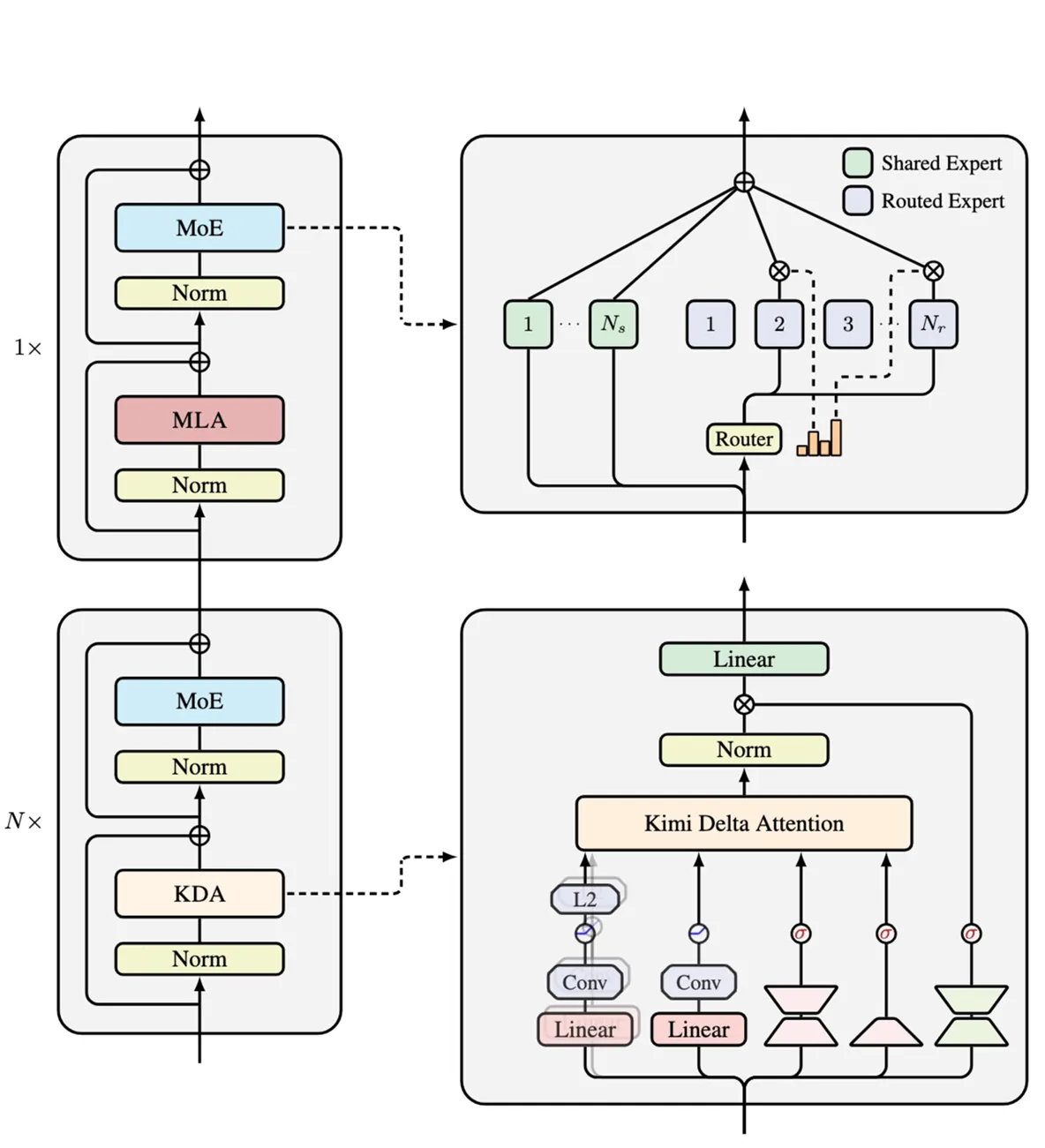
The model demonstrates resilience against long-dependency decay, intelligently discerning what information to retain and what to discard, which preserves reasoning integrity even with extremely large contexts.
These capabilities make the Kimi-Linear-48B model exceptionally well-suited for demanding applications like extended dialogues, complex reasoning chains, and reinforcement learning (RL) tasks.