Granite 4: IBM introduces a line of small but fast LLMs
While OpenAI, Anthropic, and Meta are competing with billions of parameters, IBM has suddenly decided to play a different game by introducing Granite-4.0 — a set of small but nimble LLMs.
Instead of giants with hundreds of billions of parameters, IBM has rolled out:
- Micro (3B) — an ultra-lightweight version that can easily run on a laptop.
- Tiny (7B/1B active) — a compact MoE that saves memory and tokens.
- Small (32B/9B active) — the largest in the series, but still a small one compared to top-tier LLMs.
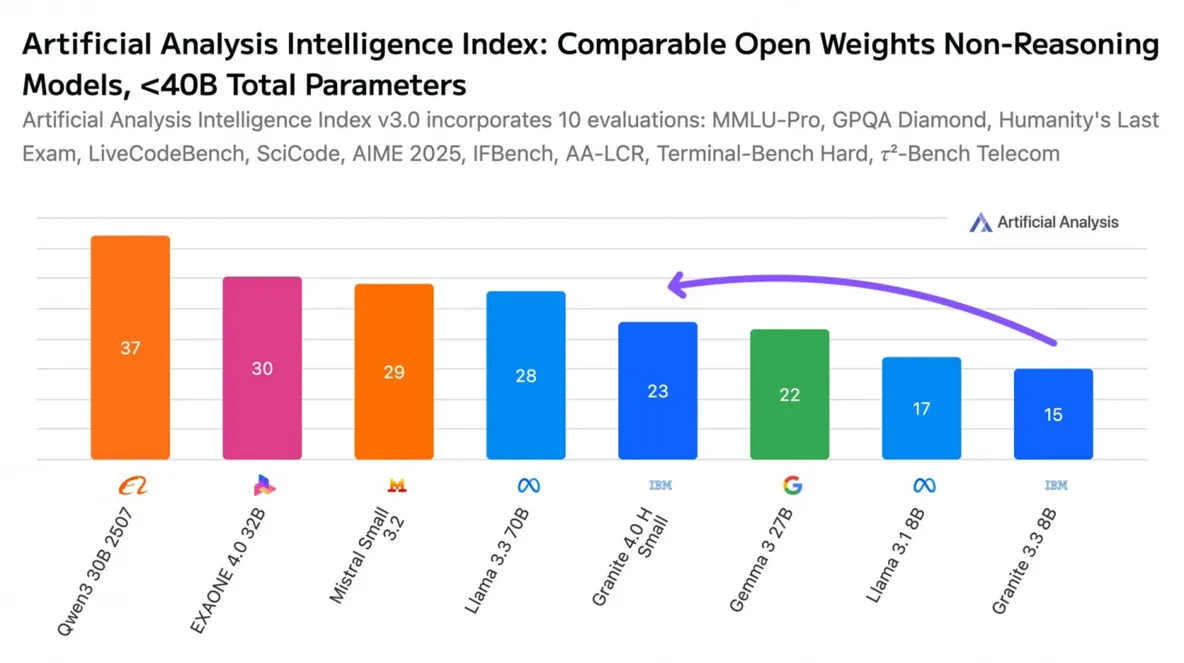
The key feature of this model series is the hybrid Mamba architecture: the model deactivates unnecessary blocks and runs faster, while maintaining a long context (up to 128K).
Perhaps this "reverse move" by IBM will become the new trend: fewer parameters, but more practical utility?
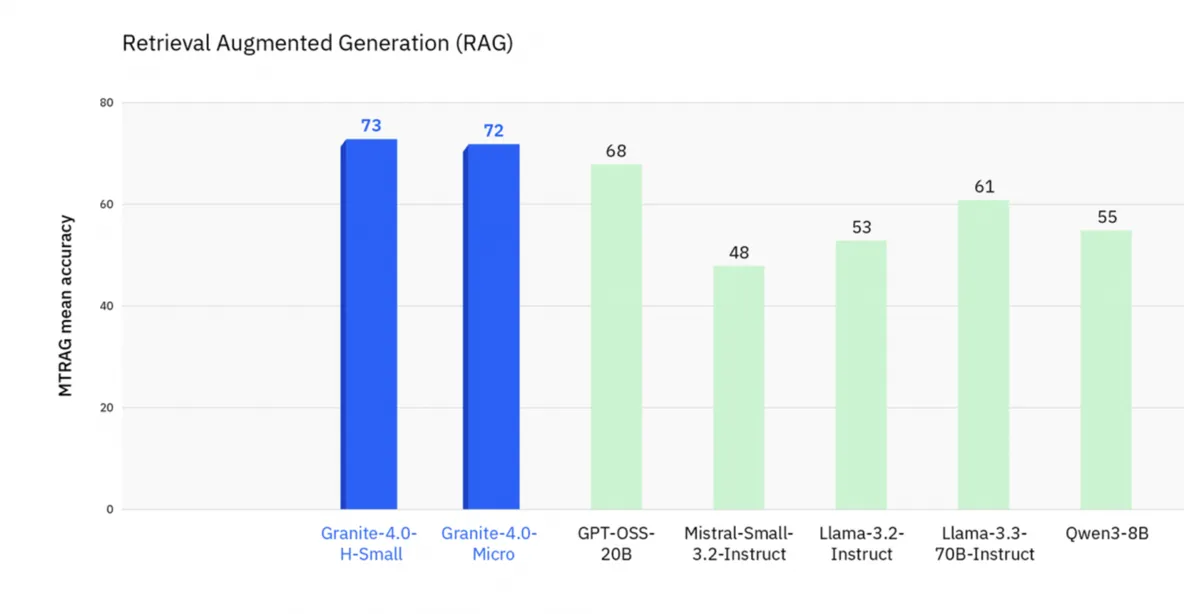
Granite-4.0 H-Small and Micro surprisingly outperform giants like Llama-3.3-70B and Qwen3-8B in Retrieval-Augmented Generation (73 and 72 versus 61 and 55).
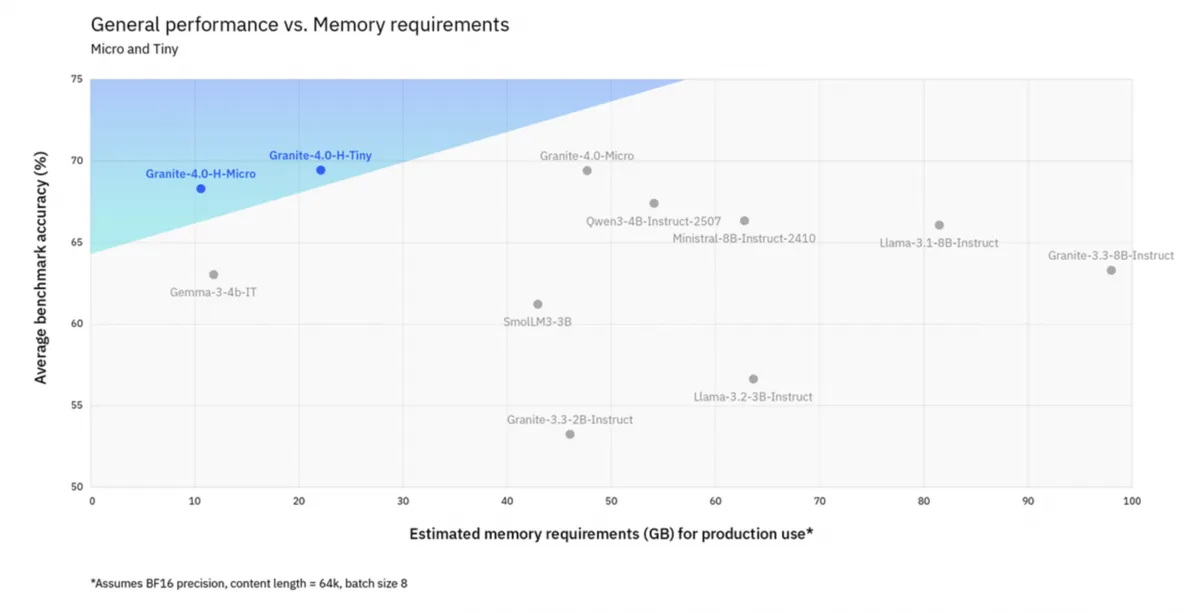
H-Micro and H-Tiny occupy the top part of the efficiency chart: they maintain an accuracy above 70% with very modest VRAM requirements.
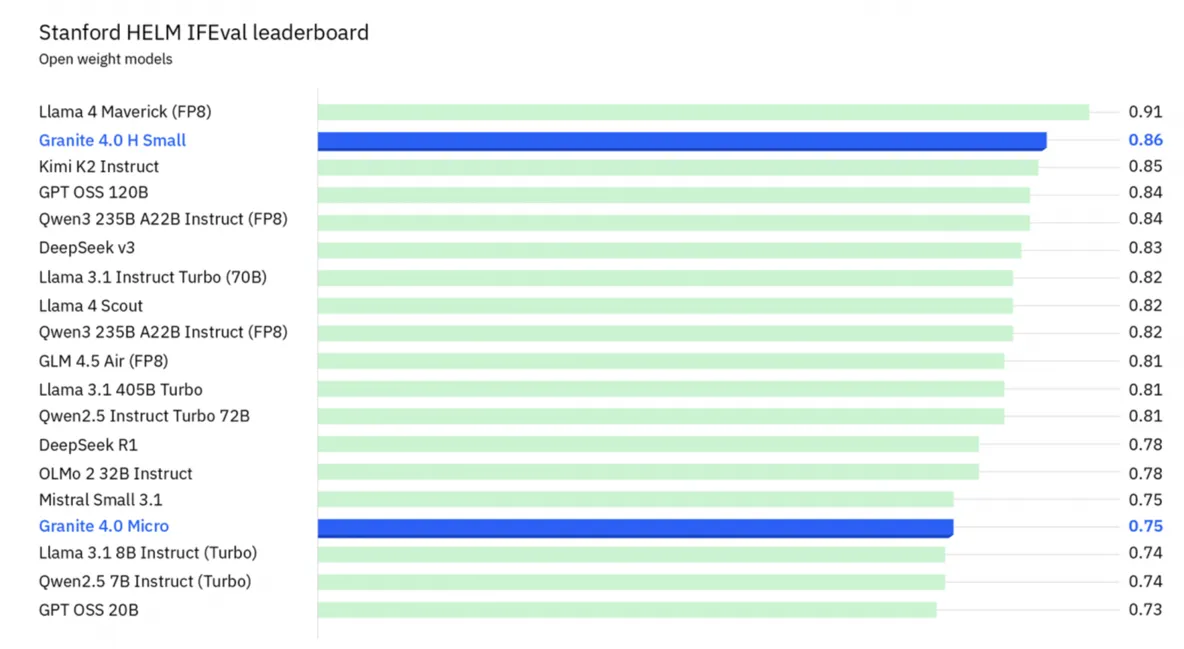
Granite-4.0 H-Small with a score of 0.86 on IF-Eval is approaching top models like Llama 4 Maverick and Kimi K2, while Micro holds a solid position in the middle of the table alongside Mistral and OLMo. For models of this size, this is a very serious statement.
By the way, these models are already available in Continue. The models are on Hugging Face.